
Retrieval-Augmented Generation (RAG), czyli generowanie wspomagane wyszukiwaniem, to architektura łącząca modele generatywne z bazami wiedzy. Zamiast polegać wyłącznie na statycznych danych z procesu trenowania, RAG pozwala modelowi najpierw wyszukać aktualne, kontekstowe informacje, a dopiero potem wygenerować odpowiedź. Dzięki temu model może tworzyć bardziej trafne i aktualne treści bez konieczności ponownego trenowania.
W klasycznym podejściu duży model językowy (LLM) odpowiada na podstawie tego, co wie – czyli na podstawie danych, na których został wytrenowany. RAG wprowadza etap wyszukiwania informacji – model najpierw pobiera dane z wewnętrznej lub zewnętrznej bazy wiedzy (dokumentów firmowych, internetu, systemu CRM), a następnie wzbogaca swoją odpowiedź o te aktualne informacje.
Znaczenie RAG dla dużych modeli językowych
Modele takie jak ChatGPT, Gemini, Claude czy LLaMA są trenowane na ogromnych zbiorach danych, ale mają ograniczoną wiedzę. Ich dane treningowe są statyczne i mają „datę ważności”. Po zakończeniu treningu nie mają dostępu do nowych informacji – co oznacza, że mogą podawać przestarzałe, niepełne lub nawet błędne odpowiedzi.
RAG eliminuje ten problem. Pozwala modelowi korzystać z aktualnych i wiarygodnych źródeł wiedzy, bez konieczności drogiego i czasochłonnego trenowania modelu od nowa. Dzięki temu systemy takie jak ChatGPT z funkcją przeszukiwania internetu czy Gemini zintegrowany z Google Search mogą generować odpowiedzi z uwzględnieniem najnowszych informacji i kontekstu użytkownika.
Generowanie odpowiedzi z wykorzystaniem modelu AI wspomaganego wyszukiwaniem
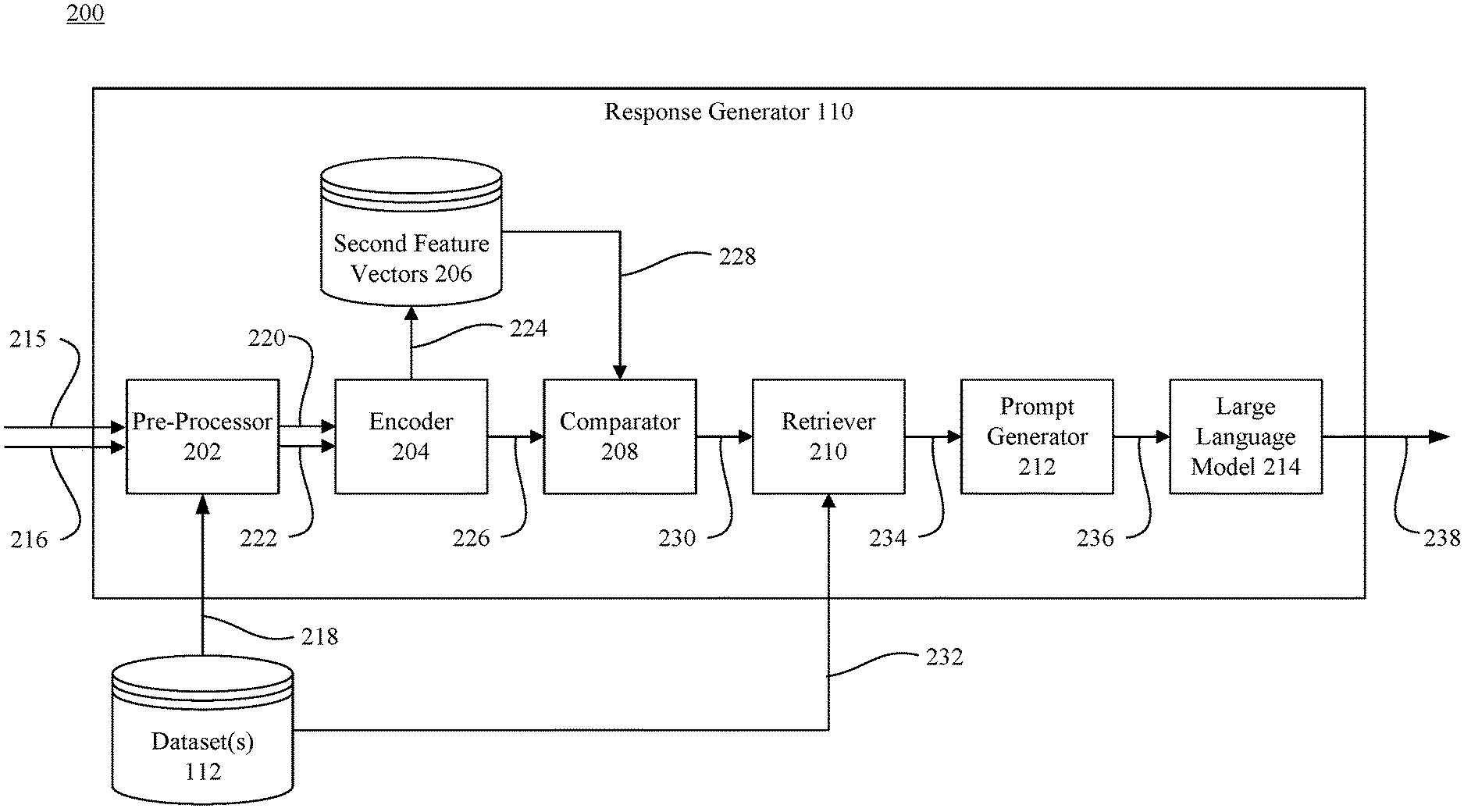
Źródło: https://patents.google.com/patent/US20240346256A1/en
W systemie opisanym w patencie US20240346256A1 model Retrieval-Augmented Generation (RAG) działa w oparciu o połączenie przetwarzania zapytania użytkownika i wyszukiwania informacji pomocniczych z bazy danych. Zapytanie trafia do modułu pre-processora, który przygotowuje je do dalszego przetwarzania, a następnie encoder przekształca je w wektor cech – tzw. pierwszy wektor cech. Ten wektor trafia do komparatora, który porównuje go z zapisanymi w bazie danych drugimi wektorami cech, obliczając ich podobieństwo przy użyciu metryki cosine similarity.
Na podstawie tych obliczeń retriever wybiera najbardziej adekwatne fragmenty danych z dataset. Są to dane, które spełniają ustalone kryteria, np. przekraczają próg podobieństwa lub należą do N najlepiej dopasowanych. Jeśli żaden wektor nie spełnia warunków, retriever może nie przekazać żadnych danych dalej. Wybrane informacje są przesyłane do generatora promptu, który łączy je z oryginalnym zapytaniem i tworzy pełny prompt dla dużego modelu językowego. Na końcu model LLM generuje odpowiedź wzbogaconą o trafne konteksty z bazy wiedzy, co zwiększa trafność, aktualność i użyteczność wygenerowanej treści.
Co konkretnie można zyskać dzięki RAG?
Stosowanie tej techniki to:
- większa trafność i aktualność odpowiedzi – dzięki połączeniu z zewnętrznymi źródłami model może uwzględniać najnowsze dane, statystyki, dokumenty czy informacje kontekstowe
- niższe koszty – RAG pozwala na adaptację modelu do potrzeb konkretnej branży, firmy lub zastosowania bez potrzeby kosztownego fine-tuningu (czyli ponownego treningu)
- większe zaufanie użytkowników – generowane odpowiedzi mogą zawierać odniesienia do źródeł lub cytaty z dokumentów, co pozwala łatwo je zweryfikować
- szersze zastosowanie LLM – RAG umożliwia wykorzystanie LLM-ów do zadań wymagających precyzyjnej wiedzy: wirtualni asystenci, chatboty, wyszukiwarki wewnętrzne, narzędzia badawcze czy silniki rekomendacji
Gdzie w praktyce można zastosować RAG?
RAG sprawdza się wszędzie tam, gdzie potrzebna jest aktualność, precyzja i kontekst:
- w obsłudze klienta (chatboty z dostępem do bazy wiedzy lub polityki firmy),
- w badaniach i analizach (np. analizy rynkowe, raporty inwestycyjne),
- w tworzeniu treści opartych na faktach (artykuły, raporty, komunikaty),
- w silnikach rekomendacji (na podstawie zachowań użytkowników i opisów produktów),
- w systemach eksperckich (np. pomoc HR, onboarding, dokumentacja techniczna).
RAG vs fine-tuning
W przeciwieństwie do fine-tuningu, gdzie model jest uczony nowych danych poprzez kosztowny proces ponownego treningu, RAG nie zmienia samego modelu. Zamiast tego przekazuje mu nowe informacje na wejściu – jako część promptu. To rozwiązanie jest znacznie szybsze, tańsze i bardziej elastyczne.
Oba podejścia można też łączyć! Model może być lekko dostrojony do konkretnego języka czy formy wypowiedzi, a RAG będzie zapewniał dostęp do świeżych i specjalistycznych treści.




")


")



