
Uczenie nadzorowane (z ang. supervised learning) to metoda uczenia maszynowego, w której model uczy się na podstawie danych wejściowych oraz przypisanych do nich etykiet (czyli prawidłowych odpowiedzi). Stanowi dziedzinę sztucznej inteligencji, która pozwala algorytmom uczyć się na podstawie danych.
W przypadku uczenia nadzorowanego model trenowany jest na zestawie danych zawierających zarówno wejścia (np. cechy, liczby, obrazy), jak i odpowiadające im wyjścia (czyli tak zwane etykiety lub wartości oczekiwane). Celem tego procesu jest stworzenie funkcji, która potrafi prawidłowo przewidywać wyjścia dla nowych, nieznanych wcześniej danych.
To właśnie te nadzorujące etykiety czynią ten typ uczenia odrębnym – model wie, jaki wynik jest poprawny i stara się zminimalizować różnicę między własną predykcją a rzeczywistością.
Jak działają algorytmy uczenia nadzorowanego?
f
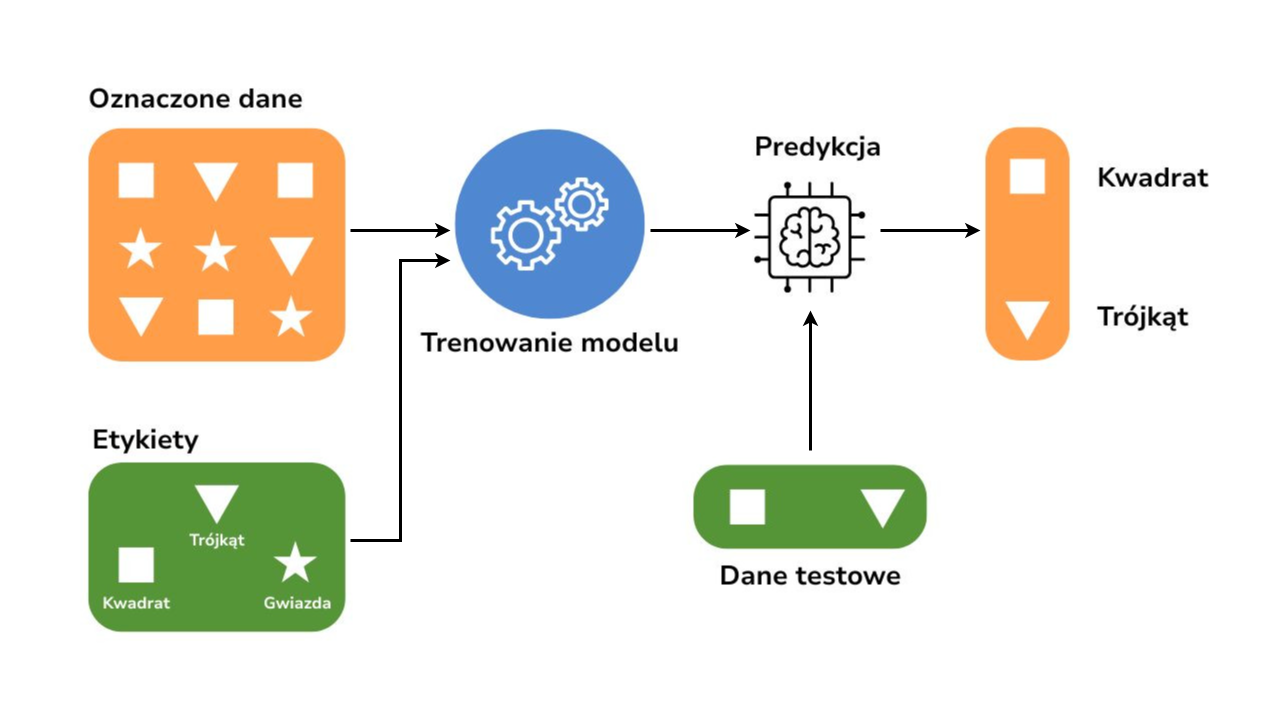
Przetłumaczone ze źródła: https://maddevs.io/blog/semi-supervised-learning-explained/
Algorytmy uczenia nadzorowanego dążą do znalezienia funkcji, która najlepiej odwzorowuje zależność między wejściami a oczekiwanymi wyjściami.
W praktyce oznacza to minimalizowanie funkcji straty, która mierzy różnicę między przewidywaniami modelu a rzeczywistymi wynikami. W tym celu stosuje się różne podejścia, między innymi minimalizację ryzyka empirycznego (z ang. empirical risk minimization) lub bardziej zaawansowaną metodę z regularyzacją – minimalizację ryzyka strukturalnego (z ang. structural risk minimization), która pozwala ograniczyć ryzyko przeuczenia.
Popularne algorytmy uczenia nadzorowanego
Wśród najczęściej stosowanych algorytmów uczenia nadzorowanego znajdują się:
- regresja liniowa,
- regresja logistyczna,
- drzewa decyzyjne,
- maszyny wektorów nośnych (SVM),
- k-NN (najbliższych sąsiadów),
- naiwne klasyfikatory Bayesowskie
- sieci neuronowe.
Każdy z nich ma swoje zalety i ograniczenia, a wybór najlepszego rozwiązania zależy od rodzaju problemu, jakości danych oraz oczekiwanej dokładności modelu.
Jak przebiega proces uczenia nadzorowanego?
Aby poprawnie przeprowadzić proces uczenia nadzorowanego, należy wykonać kilka kroków:
- Najpierw trzeba określić, jakiego rodzaju dane będą służyć jako próbki treningowe.
- Następnie zbierany jest zestaw treningowy – zawierający dane wejściowe oraz odpowiadające im wyjścia (np. ręcznie nadane etykiety). Dane wejściowe przekształca się w tzw. wektory cech, które zawierają istotne informacje opisujące każdy przypadek.
- Kolejnym krokiem jest wybór algorytmu i struktury funkcji uczącej – mogą to być np. drzewa decyzyjne, sieci neuronowe lub maszyny wektorów nośnych.
- Po zakończeniu treningu model testowany jest na osobnym zbiorze danych, by ocenić jego skuteczność.
Gdzie uczenie nadzorowane znajduje zastosowanie?
Uczenie nadzorowane znajduje szerokie zastosowanie w praktyce – od klasyfikacji obrazów, przez rozpoznawanie mowy, aż po prognozowanie cen, wykrywanie oszustw czy filtrowanie spamu. Wszędzie tam, gdzie możliwe jest przygotowanie zestawu danych wejściowych z etykietami – tam może zostać zastosowane uczenie nadzorowane.
Jakie problemy mogą wystąpić podczas uczenia nadzorowanego?
Skuteczność uczenia nadzorowanego zależy od wielu czynników. Duże znaczenie ma odpowiedni balans pomiędzy tzw. błędem bias (niedouczeniem) a wariancją (przeuczeniem).
Jeśli algorytm jest zbyt sztywny, nie nauczy się dobrze wzorców w danych. Z kolei jeśli jest zbyt elastyczny, może nauczyć się szumu lub błędów w danych, co prowadzi do nadmiernego dopasowania.
Inne problemy to m.in. nadmierna złożoność funkcji, zbyt duża liczba cech (tzw. przekleństwo wymiarowości) czy obecność szumu w danych wyjściowych (np. błędnych etykiet).











