
Uczenie nienadzorowane (ang. unsupervised learning) to podejście w uczeniu maszynowym, gdzie algorytmy uczą się na podstawie danych pozbawionych etykiet. Oznacza to, że system nie otrzymuje gotowych odpowiedzi ani informacji o tym, co dane oznaczają – jego zadaniem jest samodzielne wykrywanie ukrytych wzorców, struktur lub zależności w surowych danych.
W przeciwieństwie do uczenia nadzorowanego, gdzie dane są opatrzone konkretnymi etykietami (np. spam vs nie-spam), tutaj model próbuje zrozumieć strukturę danych bez zewnętrznej pomocy.
Jak działa uczenie nienadzorowane?
W procesie uczenia nienadzorowanego algorytm analizuje dane wejściowe i na ich podstawie identyfikuje powtarzalne wzorce, podobieństwa lub różnice.
Przykładowo, może pogrupować podobne dane w klastry (klasteryzacja), znaleźć kierunki największej zmienności w danych (redukcja wymiarów), albo odkrywać tzw. zmienne ukryte, które wyjaśniają strukturę zbioru danych.
Wszystko to odbywa się bez jakichkolwiek podpowiedzi co do tego, jaka powinna być poprawna odpowiedź.
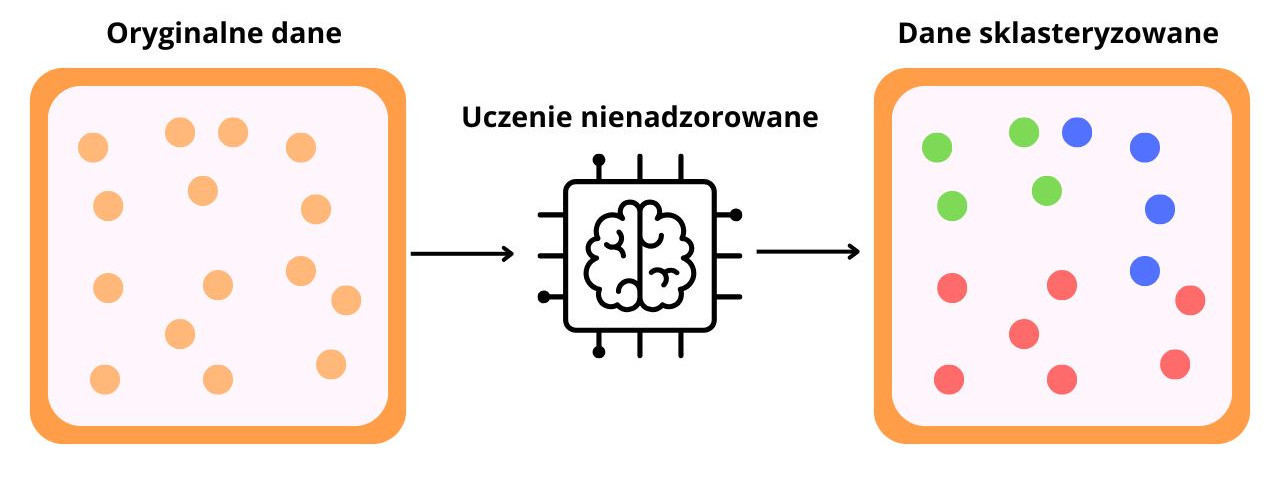
Na powyższej ilustracji przedstawiono działanie algorytmu uczenia nienadzorowanego w kontekście klasteryzacji – jednej z najczęściej stosowanych technik w tego typu uczeniu.
Punkty w takim schemacie to po prostu pojedyncze obserwacje – czyli dane wejściowe, które algorytm analizuje. Każdy punkt reprezentuje jeden obiekt opisany przez zestaw cech liczbowych, na przykład:
- klient (wiek, liczba zakupów, wartość koszyka),
- dokument (częstotliwość słów),
- transakcja (kwota, czas, miejsce).
W uczeniu nienadzorowanym, szczególnie przy klasteryzacji, takie punkty traktuje się jako elementy w przestrzeni wielowymiarowej, a algorytm szuka między nimi podobieństw – np. na podstawie odległości – żeby podzielić je na grupy.
Po lewej stronie widzimy oryginalne dane – punkty rozmieszczone w przestrzeni bez żadnej informacji o ich przynależności do grup. To dane nieetykietowane, czyli typowy przypadek w uczeniu nienadzorowanym. Algorytm nie wie, które punkty powinny być razem, nie ma żadnych gotowych odpowiedzi.
W środkowej części grafiki znajduje się graficzna reprezentacja algorytmu uczenia nienadzorowanego, który analizuje zależności między punktami. Na tym etapie algorytm przygląda się danym i próbuje ustalić, które punkty są do siebie najbardziej podobne.
Po prawej stronie widzimy dane sklasteryzowane – te same punkty, ale pogrupowane kolorystycznie. Każdy kolor oznacza inny klaster, czyli grupę punktów, które według algorytmu mają ze sobą najwięcej wspólnego (są blisko siebie w przestrzeni cech). To efekt działania algorytmu, który samodzielnie odkrył logiczny podział danych – bez jakiejkolwiek ingerencji człowieka.
Popularne algorytmy uczenia nienadzorowanego
Do najczęściej stosowanych metod uczenia nienadzorowanego należą:
- algorytmy klasteryzujące (np. k-means, DBSCAN),
- metody redukcji wymiarowości (takie jak PCA – analiza głównych składowych),
- autoenkodery,
- sieci Boltzmanna,
- algorytmy wykrywania anomalii (np. Isolation Forest, Local Outlier Factor).
Każdy z tych algorytmów ma swoje specyficzne zastosowania – od analizy dużych zbiorów tekstu, przez rozpoznawanie struktur w danych obrazowych, aż po wykrywanie nieprawidłowości w danych finansowych.
Przykłady zastosowań uczenia nienadzorowanego
Uczenie nienadzorowane jest szeroko wykorzystywane w takich zadaniach jak segmentacja klientów (na podstawie ich zachowań), wykrywanie oszustw, analiza tematyczna tekstów (np. modelowanie tematów), kompresja danych, a także generowanie nowych treści – jak w przypadku autoenkoderów czy modeli typu VAE (Variational Autoencoder).
Często jest też wykorzystywane jako pierwszy etap w bardziej złożonych systemach, przygotowując dane do dalszego przetwarzania przez modele nadzorowane.
Zalety i ograniczenia uczenia nienadzorowanego
Największą zaletą uczenia nienadzorowanego jest brak konieczności etykietowania danych – co znacznie obniża koszty i umożliwia wykorzystanie ogromnych, surowych zbiorów (np. tekstów z internetu).
Z drugiej strony, brak informacji zwrotnej sprawia, że trudniej jest ocenić jakość wyników, a same algorytmy mogą wykrywać wzorce, które nie mają sensu z perspektywy człowieka.
Dodatkowo, wyniki mogą być wrażliwe na jakość i strukturę danych, a także na dobór parametrów modelu.
Uczenie nienadzorowane wspierane przez inne metody
W praktyce granica między uczeniem nienadzorowanym a innymi podejściami (np. uczeniem nadzorowanym) często się zaciera.
Modele często łączą różne podejścia – np. używają uczenia nienadzorowanego do wstępnego trenowania sieci, a potem są doucza w sposób nadzorowany.
Przykładem może być BERT – model językowy, który uczy się przez maskowanie słów (bez etykiet), a potem wykorzystywany jest do konkretnych zadań językowych.







")



